Supervision verdicts
4
Discrete output classes
APPROVE, ROUTE, HARD_STOP, or REQUEST_MORE_INFO. Bounded outputs make the verdict testable; ambiguity is engineered out by construction.
Epistemology
Clinical AI does not earn institutional trust by being smart. It earns it by being defensible. Every claim must be testable. Every supervision verdict must be auditable. Every standard must be hard to vary without breaking the explanation.1
This is what we mean when we say "Popperian." It is also why our agents are named after Popper, Deutsch, Hermes, and Bench, each name carries epistemic information about the agent's role in the architecture. Read the essay →
Figure 1.1

By the numbers
Supervision verdicts
4
APPROVE, ROUTE, HARD_STOP, or REQUEST_MORE_INFO. Bounded outputs make the verdict testable; ambiguity is engineered out by construction.
Grounding hierarchy
5
Each rule traces to one of five source tiers: regulatory floor, standards from the societies that write them, peer-reviewed evidence, professional guidelines, or emerging evidence. The engine refuses to load a rule whose grounding is missing or inverted.
Independence
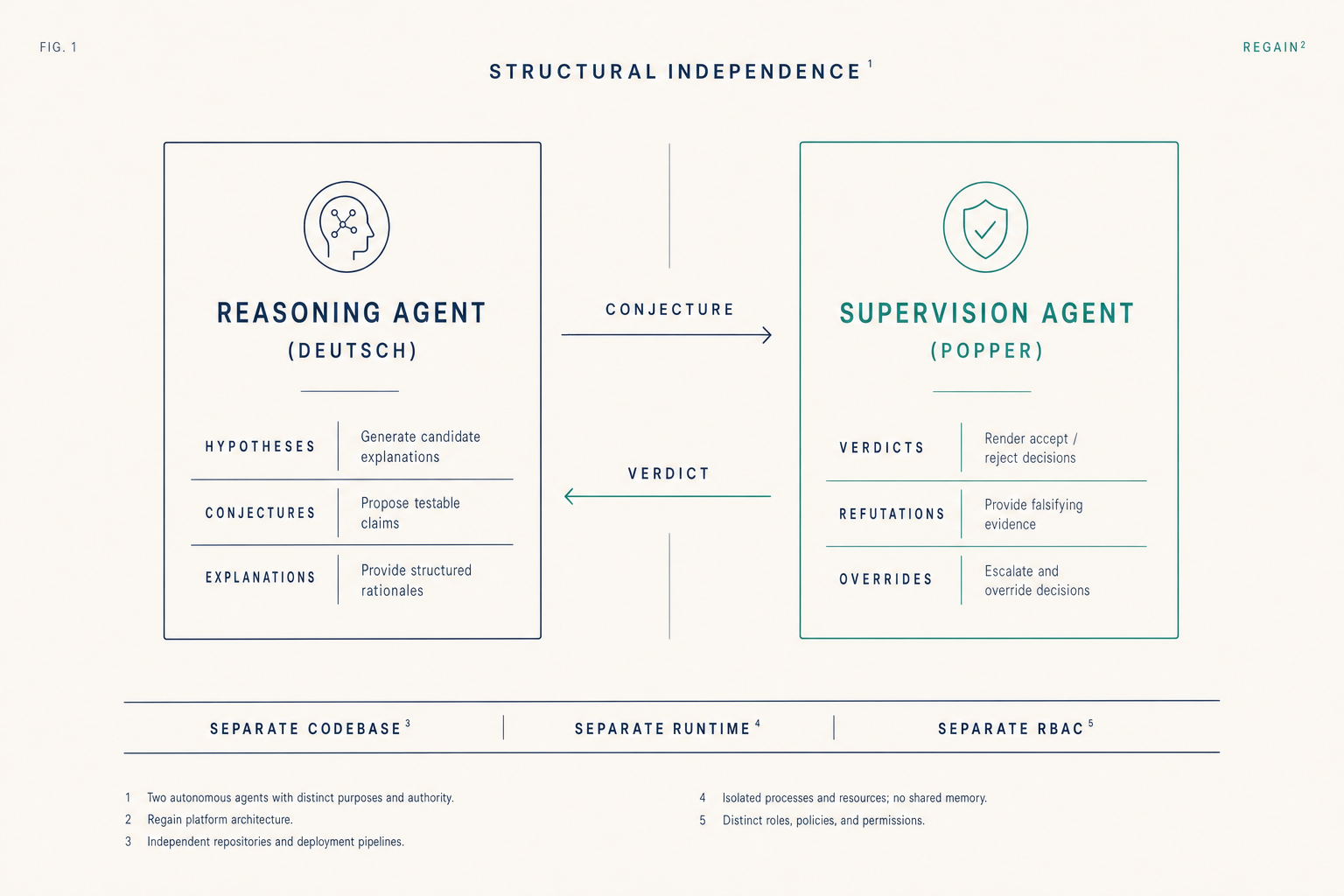
2
Reasoning (Deutsch) and supervision (Popper) are structurally independent, separate codebase, separate runtime, separate access controls. The supervisor cannot be silenced by the reasoner.
Four commitments
Three architectural commitments fall out of the philosophy. A fourth, naming, is what keeps the discipline visible to anyone reading the codebase.
01
Every compliance rule traces to a published standard, guideline, or regulatory requirement. No interpretive ambiguity, no orphan claims.
02
Same inputs always produce the same outputs. Reproducibility is not a nice-to-have; it is what makes the engine an evaluator at all.
03
The supervision agent is structurally independent of the reasoning agent, separate codebase, separate runtime, separate access controls.
04
Each agent's role mirrors the philosophical position it is named for: Popper supervises, Deutsch reasons, Hermes carries, Bench tests.
Conjecture
Karl Popper's contribution to the philosophy of science was the insight that a theory's value lies not in how often it is confirmed but in how readily it could be falsified.1 A theory that explains everything explains nothing. A theory that risks something, that forbids specific outcomes, is the kind that science can advance.
We apply this standard to clinical AI. Our reasoning agent (Deutsch) is built to make specific, falsifiable conjectures about a patient's condition. Our supervision agent (Popper) is built to test those conjectures against published evidence and return one of four verdicts: APPROVE, ROUTE, HARD_STOP, or REQUEST_MORE_INFO. The conjecture-refutation loop is the architecture, not a slogan.
Hard to vary
David Deutsch refined Popper's framework with a second criterion: a good explanation is one that is hard to vary while still accounting for what it claims to explain.2 Change one element and the explanation collapses. Most popular health claims fail this test: the underlying causal story can be rewritten freely without affecting the recommendation. Our compliance rules are written to survive this test.
Naming
Deutsch makes conjectures. Popper refutes them. Hermes carries the messages between them under a strict contract. Bench tests both against clinical vignettes and scores the results. The naming is not decorative. Each agent's role in the architecture mirrors the philosophical position it is named for. When an engineer reads the codebase, the names carry epistemic information, which is itself a discipline our domain doesn't otherwise enforce.
Application
Three commitments fall out of this epistemology. First: every compliance rule traces to a published standard, guideline, or regulatory requirement, no interpretive ambiguity. Second: the evaluation engine is deterministic and reproducible, same inputs always produce the same outputs. Third: the supervision agent is structurally independent of the reasoning agent, separate codebase, separate runtime, separate access controls.
These are not engineering preferences. They are epistemological requirements. A compliance evaluation that cannot be audited is not a compliance evaluation. A safety verdict that the reasoning engine can override is not a safety verdict. We built the architecture this way because the alternative is theater.
Figure 3.1, Five-source grounding hierarchy
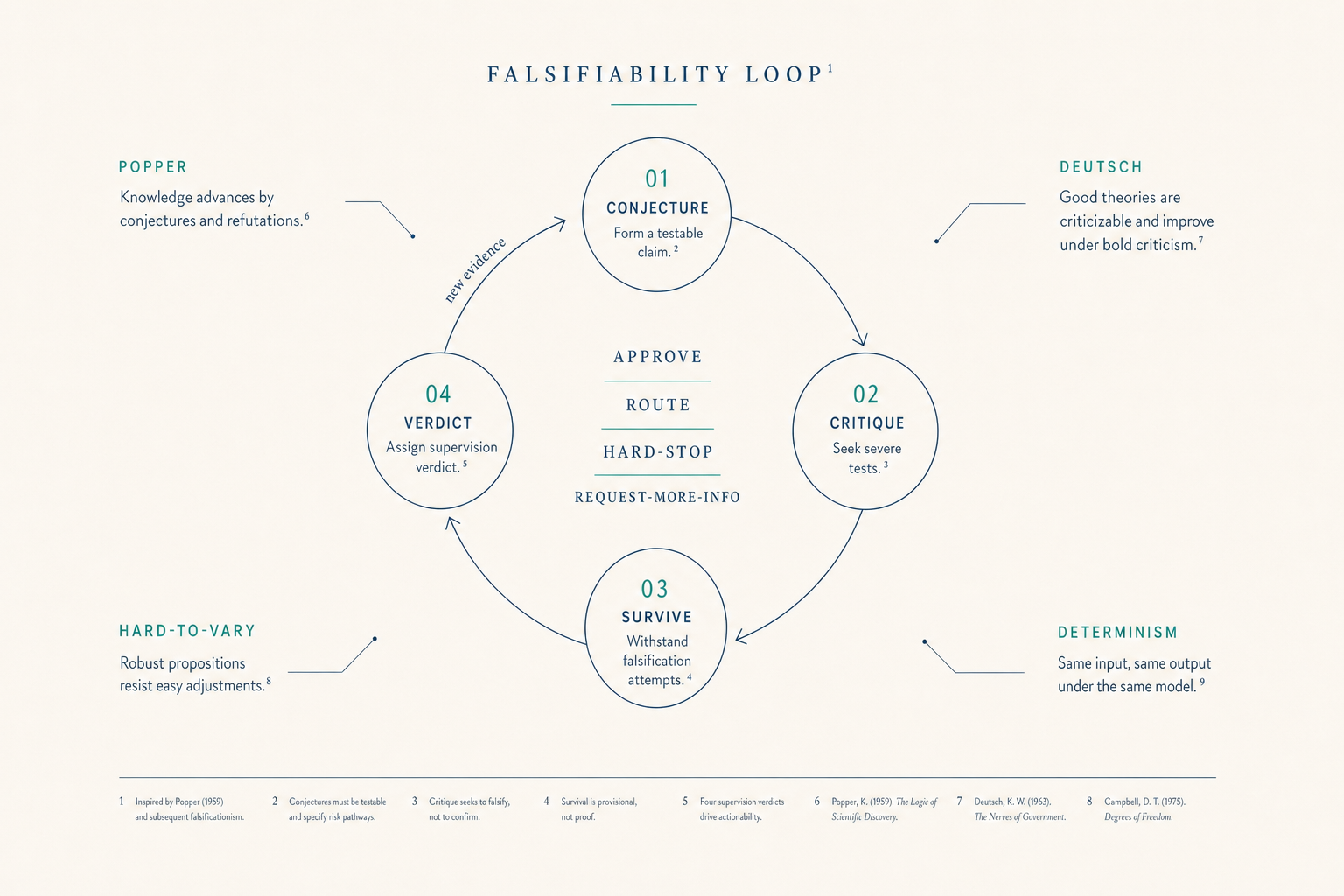
Figure 4.1
Read more
A deeper dive into the epistemological standard we apply to clinical reasoning, explanations that resist alteration without breaking the explanation.
Hard to Vary deep dive →Security architecture, deterministic evaluation, HIPAA posture, and open standards, the engineering decisions that make the platform auditable.
See the trust architecture →An infrastructure company, not a SaaS dashboard. Self-funded, two-org structure, clinical systems deployed at medical centers in Central Asia.
Back to the About hub →Footnotes