Mechanisms
9
Distinct epistemic mechanisms
ArgMed debate, hard-to-vary scoring, falsification criteria, IDK protocol, safety routing, clinician feedback loop, composable domains, rules-as-data, accuracy ascertainment.
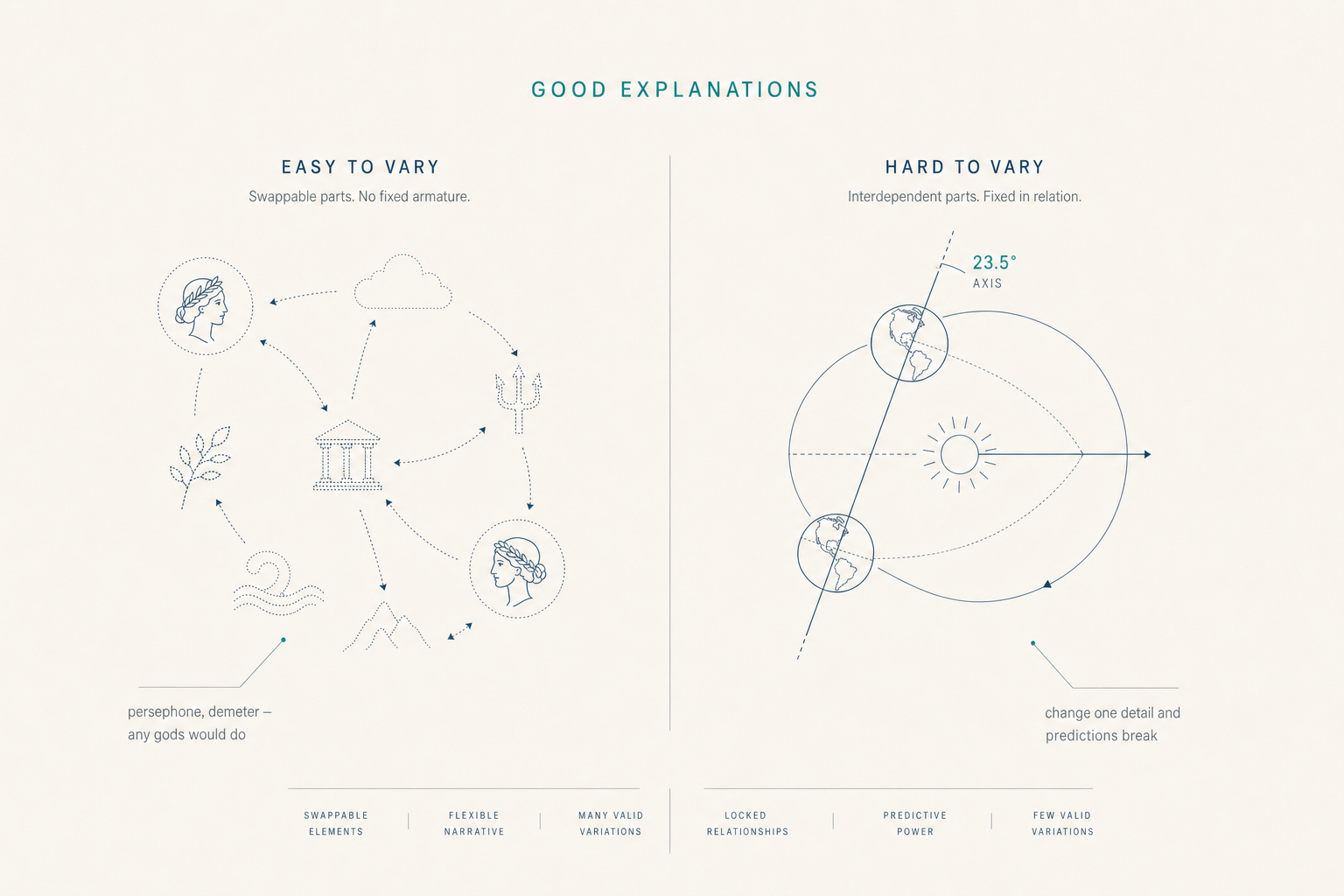
Hard to Vary
Most healthcare AI systems optimize for prediction accuracy. We optimize for explanation quality. The difference: predictions can be right for wrong reasons and silently fail when conditions change. Explanations that are hard to vary — where every component is load-bearing — remain correctable and auditable even when wrong.1
The standard is Karl Popper's. The criterion is David Deutsch's refinement. The architecture below operationalizes both. See the mechanisms →
Figure 1.1
“The quest for good explanations is, I believe, the basic regulating principle not only of science, but of the Enlightenment generally.”
David Deutsch — The Beginning of Infinity
Engineering facts
Mechanisms
9
ArgMed debate, hard-to-vary scoring, falsification criteria, IDK protocol, safety routing, clinician feedback loop, composable domains, rules-as-data, accuracy ascertainment.
Verdicts
4
APPROVE, ROUTE, HARD_STOP, REQUEST_MORE_INFO. Bounded outputs make every verdict testable; ambiguity is engineered out by construction.
HTV score
0.0–1.0
Four-dimensional algorithm — interdependence, specificity, non-ad-hocness, falsifiability — scored per claim. Low-HTV explanations route to a clinician.2
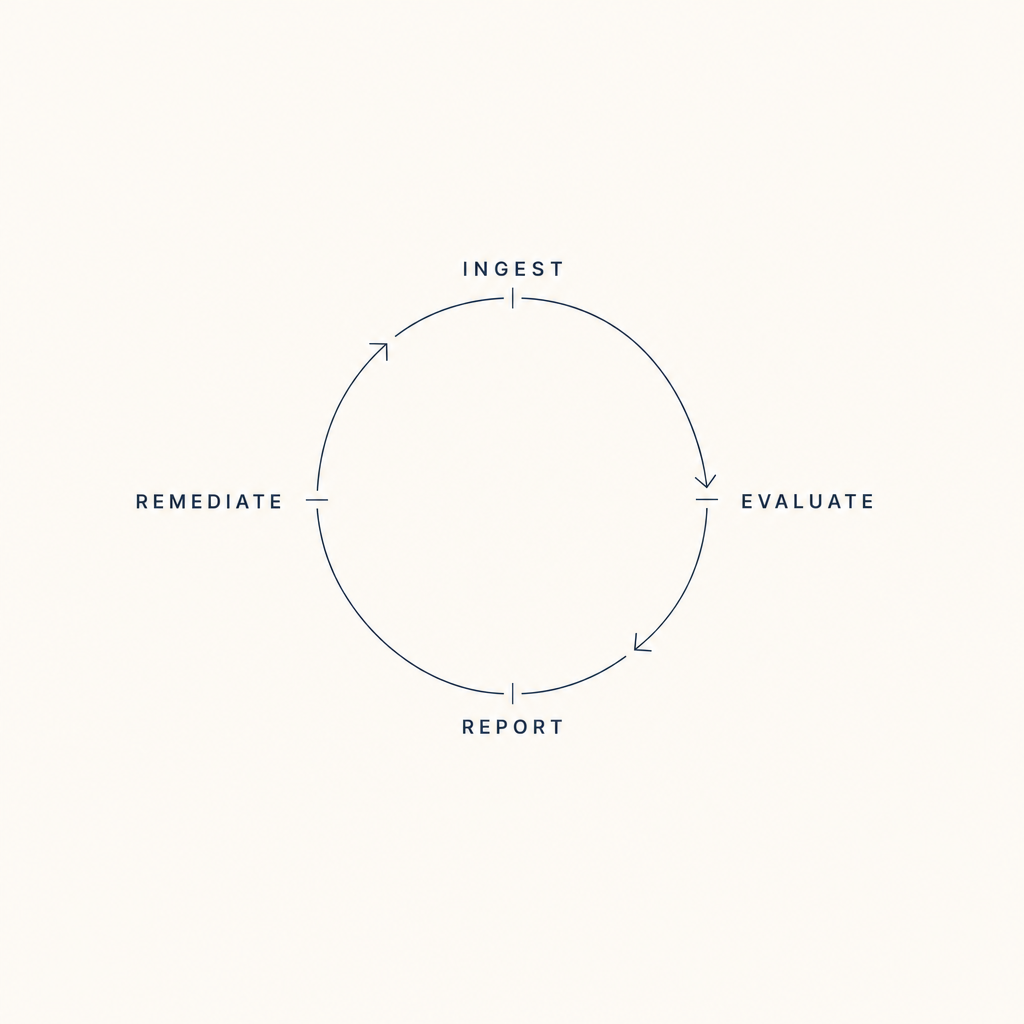
The cycle
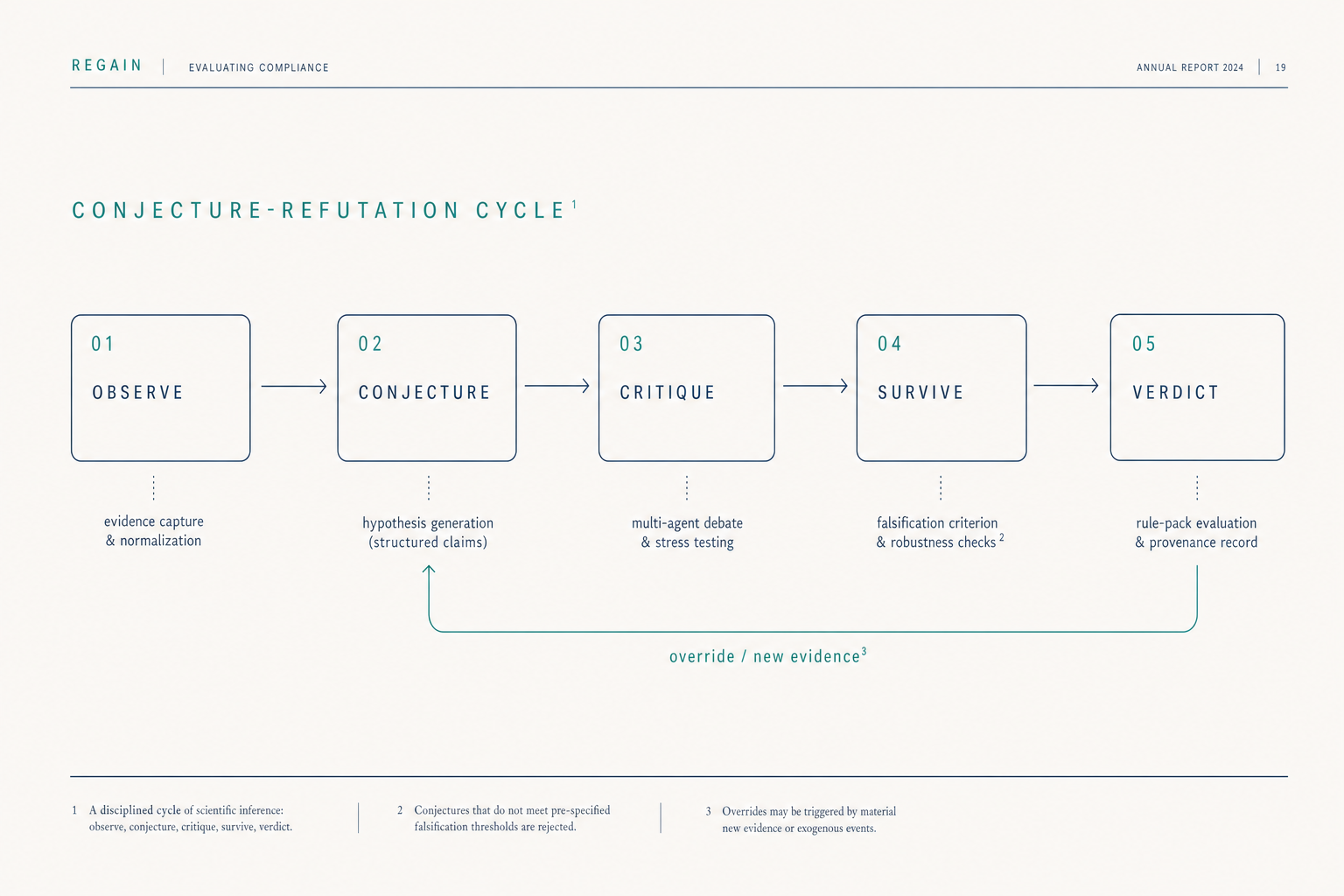
Popper's contribution to the philosophy of science was the insight that a theory's value lies not in how often it is confirmed but in how readily it could be falsified. We apply this standard to clinical AI as a five-stage operational loop.
01
Clinical observation enters as structured evidence — typed, hashed, provenance-tagged. No free-text intermediation between source and reasoning.
02
The reasoning agent (Deutsch) proposes specific, falsifiable explanations — not probability distributions over possibilities. Each conjecture must specify what would prove it wrong.
03
Multiple agents attack the conjecture adversarially. The hard-to-vary score is computed across interdependence, specificity, non-ad-hocness, and falsifiability.
04
Surviving conjectures pass to the supervision agent (Popper), structurally independent of the reasoner. Same input, same verdict — deterministic.
05
APPROVE, ROUTE, HARD_STOP, REQUEST_MORE_INFO. Each verdict carries its evidence hash, its falsification criteria, and the override path back into step 02.
Mechanisms
Multi-agent generator → verifier → reasoner pipeline. Generate hypotheses, attack each adversarially, keep only the survivors.
Quantify how hard to vary each explanation is on a 0.0–1.0 scale across interdependence, specificity, non-ad-hocness, and falsifiability.
Twelve specific uncertainty triggers with structured responses. The system admits what it does not know, in a form a clinician can act on.
Every claim specifies what would prove it wrong. Claims without falsification criteria are rejected at the conjecture stage.
High-risk decisions and low-HTV verdicts route to a human clinician. The default is approval; the surface area for automation is bounded by epistemic confidence.
Overrides actively change future reasoning for that patient. Override tracking carries confidence decay over time.
Medication, nutrition, exercise, sleep, mental health — the same epistemic principles compose across all clinical domains.
Interaction rules are explicit, versioned, auditable data. The deterministic policy engine enforces safety boundaries; rule packs declare them.
We measure our own predictions against outcomes. Reproducibility is the precondition for the loop in step 06 to compound.
The thesis
Both stories account for the seasons. The first one is easy to vary: substitute any gods, any emotions, any relations — the explanation still "works." The second one is hard to vary: change the tilt angle and the predictions break, change the orbital plane and the hemispheres flip, change the seasons and the geometry no longer accounts for them.
Most healthcare AI today is Persephone. It produces answers that sound plausible because the underlying causal story can be rewritten without affecting the recommendation. We chose the harder constraint: every architectural commitment in this section is what it takes to ship Earth's-tilt-grade explanations.
Figure 3.1 — Hard-to-vary scoring, four dimensions

Figure 4.1
Why this matters
Your clinician stays in control — medication changes are always reviewed and approved. Explanations come with reasons. The system tells you when it does not know. Decisions are grounded in your specific situation, not generic advice.
The AI proposes start / stop / titrate / hold; you decide. Audit trails carry epistemological metadata for every decision. Low confidence triggers routing to you. Your overrides actively change future recommendations.
Error correction over error prevention. Fallibilism over certainty. Explanation over prediction. The architecture refuses to accept a verdict it cannot justify and refuses to silence a correction it cannot integrate.1
Read more
How we know what we know — the Popperian foundation, the four supervision verdicts, and the structural independence between reasoning and supervision.
Read the approach →Security architecture, deterministic evaluation, HIPAA posture, and open standards — the engineering decisions that make every claim above auditable.
See the trust architecture →An infrastructure company, not a SaaS dashboard. Self-funded, two-org structure, clinical systems deployed at medical centers in Central Asia.
Read about Regain →We will trace any clinical claim from the source observation to the surviving conjecture to the supervision verdict, and answer the epistemological question against the codebase, not the brochure.
Request a demoFootnotes